
Modeling Online News Popularity
In my previous article on Studying Online News Popularity we used data collected in 2015 by researchers from the Universities of Porto and Minho in Portugal (using ~39000 articles that had been published on Mashable between January 7 2013 to January 7 2015) to examine the relationship between the type and publishing day of an article to its popularity.
In this article we will examine the use of this dataset to build predictive Linear and Tree based models.
The data is mostly clean but there was some work required to combine columns, that were essentially One Hot Encoded, into Categorical columns for Data Channel and Day of the Week data as well some scripting to fill in some missing Data Channel values.
The main reason for this is that while One Hot Encoding is good for linear models, the tree based models perform better with Ordinal Encoding for Categorical data.
The Dataset
As previously mentioned this is a large dataset with ~39000 observations of some 50 attributes. Two of them, namely url and timedelta (the difference between the date the article was downloaded and the date of its publications) are non-predictive and can be discarded. That leaves 47 predictive and 1 target attribute shares(the number of views for the article).
The problem was changed to one of Classification by creating a new target attribute popularity with 2 classes, popular(1) and unpopular(0)— set to a value of 1 if shares > 1400 and 0 otherwise, where 1400 is the median shares value.
. The distribution of popularity values was reasonably balanced with 53% popular(1) and 47% unpopular(0).
The url, timedelta and shares attributes were then dropped from the dataset.
Data Modeling
Since the distribution of popularity values is balanced, accuracy makes a good evaluation metric with the baseline accuracy value being the percentage of the largest class, expressed as a fraction i.e. the baseline accuracy for the entire dataset would be 0.53.
Partitioning
Since the dataset is large, sklearn.model_selection.train_test_split was used twice to split it into Training(64%:25372), Validation(16%:6343) and Test(20%:7929) datasets.
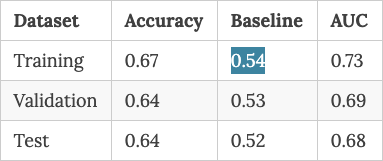
The baseline accuracy measures for the Training, Validation and Test datasets are 0.54, 0.53 and 0.52 respectively.
Linear Model — Logistic Regression(LogisticRegression with SelectKBest)
For the Linear Model, the data was transformed by using OneHotEncoder() and then scaled using StandardScaler().
The SelectKBest() function was used to compute the best k features which were then used to train a LogisticRegression() model. This process was repeated for k ranging from 1 to 62(the total number of features) and the models evaluated against the Validation dataset.
We get a best k value of 51 and the best model has an accuracy of 0.66 against the Validation dataset.
Evaluation Metrics
Using the best model gives us the following accuracy/auc scores for the Training, Validation and Test datasets:

Here’re the Confusion Matrix and ROC curves for the Test dataset

Understanding the Model
Here’s a visualization of the coefficients associated with the 51 features used for the model.

Tree Based Model — Decision Tree(DecisionTreeClassifier)
For the Decision Tree model, the categorical data was encoded using OrdinalEncoder() and the max_depth hyperparameter for the DecisionTreeClassifier() was tuned to 7using the Validation dataset.
Evaluation Metrics
The Decision Tree model gives us the following accuracy/auc scores for the Training, Validation and Test datasets:
Here’re the Confusion Matrix and ROC curves for the Test dataset

Tree Based Model — Random Forest(RandomForestClassifier)
For the Random Forest model, the OridinalEncoder() was used again for the categorical features and the model hyperparameters were tuned as shown below using the Validation dataset:
rf_model = RandomForestClassifier(n_estimators=103, random_state=42, n_jobs=-1, max_depth=25, min_samples_leaf=3, max_features=0.3)Evaluation Metrics
The Random Forest model gives us the following accuracy/auc scores for the Training, Validation and Test datasets:

Here’re the Confusion Matrix and ROC curves for the Test dataset

Understanding the Model
Feature Importance
The following table details the weight/importance, computing using PermutationImportance(), of the various features used in the model:

Partial Dependence Plots(PDP)
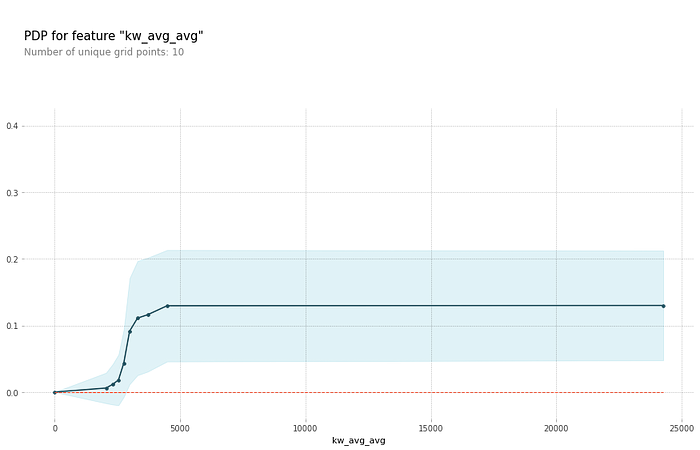
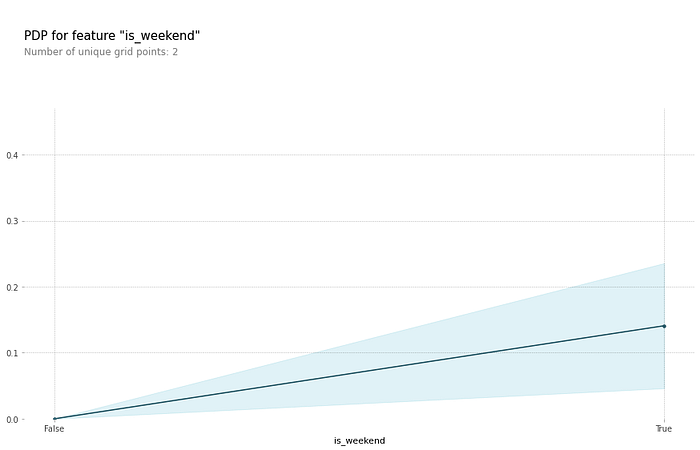
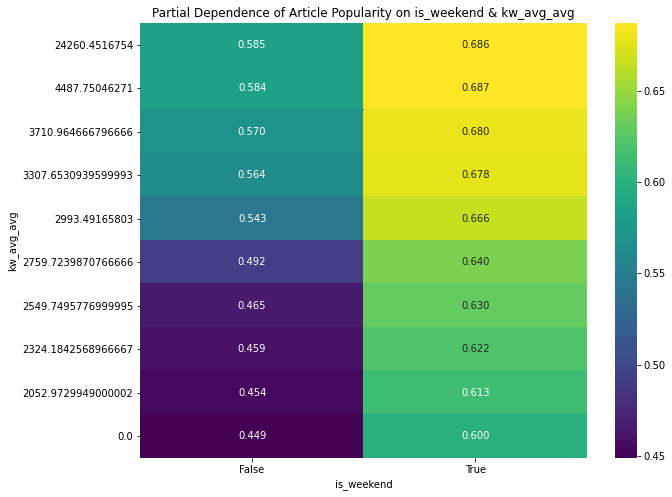
Since the 2 most important features were kw_avg_avg and is_weekend, let’s examine the Partial Dependence Plots for them in isolation and interacting.
kw_avg_avg in isolation:
is_weekend in isolation:
kw_avg_avg, is_weekend interacting:
SHAP Plots
To get a better understanding of the impact of various features on predictions, here’re SHAP (SHapley Additive exPlanations) plots of
An entry accurately predicted as popular(1)

and
One accurately predicted as unpopular(0)

Tree Based Model — Gradient Boosting(XGBoost)
For the Random Forest model, the OridinalEncoder() was used again for the categorical features and the model hyperparameters were tuned as shown below using the Validation dataset:
xgb_model = XGBClassifier(n_estimators=1000, random_state=42, n_jobs=-1, max_depth=13, learning_rate=0.3)eval_set = [(X_train_encoded, y_train),
(X_val_encoded, y_val)]
eval_metric = 'error'
xgb_model.fit(X_train_encoded, y_train,
eval_set=eval_set,
eval_metric=eval_metric,
early_stopping_rounds=200)
Here’s the resulting Validation Curve:
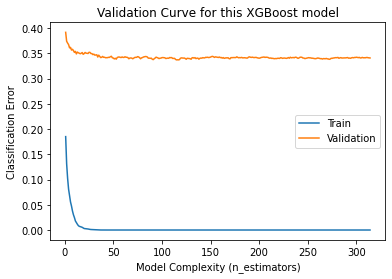
Evaluation Metrics
The Gradient Boosting model gives us the following accuracy/auc scores for the Training, Validation and Test datasets:
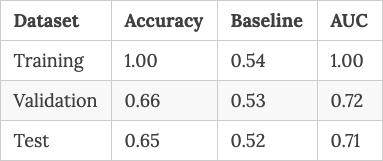
Here’re the Confusion Matrix and ROC curves for the Test dataset

Conclusion
The Random Forest model exhibited the best behavior, closely followed by Gradient Boosting and Linear models with the Decision Tree model trailing behind.

